What is Machine learning? How It Works and Why It Matters
Technology is moving fast and everyone wants to use the latest trends to solve complex problems faster. For that, we have to adopt new techniques and build long-lasting scalable solutions. One such trending technology is “Machine Learning applications”. We hear a lot about it! It is now becoming essential to use Machine learning due to the growing data size and number of internet users.
How does Machine Learning Work?
Think of an eCommerce website, like Amazon or eBay, having millions of users placing huge amounts of orders every day. How do these giants study customer behaviour and make decisions quickly to keep their business running smoothly? How do they recommend products or offers to users? It’s all handled by machine learning services in the background, which keeps churning out the huge data generated by different actions taken by their millions of customers!
Similar to how humans learn anything – See, Observe, Understand, Remember and Learn so next time they can utilize that knowledge – a computer program learns about a specific input data, a user action or anything which basically adds to its knowledge about different patterns so that the machine learning application can apply that knowledge to solve a complex problem. And believe me, it’s not magic!
Machine Learning Process: Explain in details
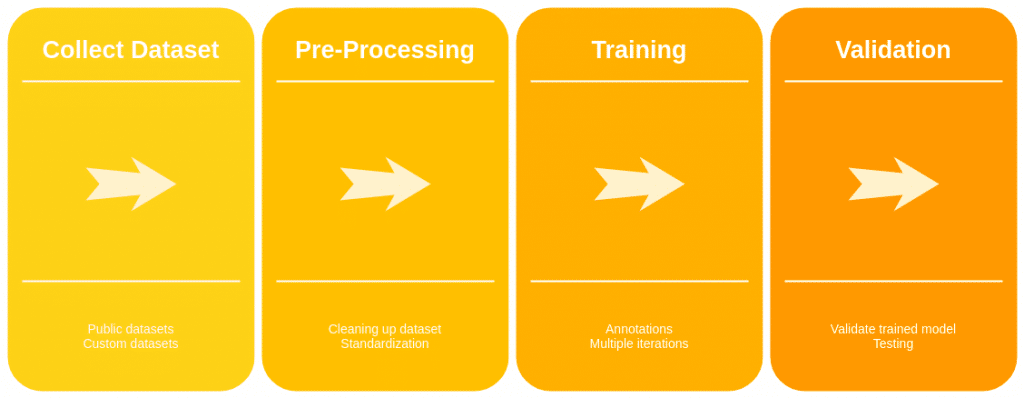
As shown in the above diagram, there are four different stages for machine learning, This is a common process for any sort of machine learning algorithm.
1. Collect Dataset
The most important aspect of machine learning applications is data, which is going to be fed to the machine for training. For example, eCommerce website user’s purchase history. It can tell many different aspects like user’s profile, demographics, age, like and dislike, buying capacity etc. One can prepare a nice recommendation engine based on such data.
There are many public datasets available for different problems – like, images of cars at traffic points. We can collect such public datasets to train our model. But for most business problems, we need to prepare a custom dataset – either by taking help from the customer or by data augmentation.
To train a machine in an appropriate manner, there should be a sufficient size of data available.
2. Pre-Processing
Now once we have the data, we simply cannot use it for training the machine. Before we can move ahead, we need to ensure that the whole dataset is in a standard format as expected and have sufficient use cases covered.
For example, an image dataset would need to,
- have all the images of standard format and resolution. If not, we need to programmatically handle that and convert all of them to a standard size and format.
- Have all images enhanced to be read in a better way.
This step ensures that we have verified the dataset properly and made necessary changes to avoid any glitches/errors in the training process. If training happens on incomplete/wrong dataset then the results would be wrong.
3. Training
Once we have the dataset ready, we can now start annotating the data for the machine. Annotation is, providing all the feature details to the machine about each and every data item in the dataset.
For example, for an image dataset, we have to annotate each image by defining different regions on it so that the machine can understand what features it has to read from this image. These annotations will be used by the machine in the training process.
Once annotations are done, we finally run the training process which creates knowledge data – think of it as a matrix having knowledge about each data item and its features provided in the annotation. This “knowledge data” is called a “model”, a flat-file containing all the knowledge about different features as per dataset.
This machine learning model will be used in future for any new input data from the user/system to identify/predict the features. For example, a new user registers on an eCommerce platform, but even without having any purchase history the platform would recommend some products based on the machine learning algorithm – may be based on user’s demographics/age/gender etc it can predict what this user might like.
4. Validation
Once the training is done, we need to validate the generated model against a small validation dataset so that we can measure the accuracy – Actual vs expected results.
Usually, training – validation dataset size is kept 70-30%. After this step, we would have an idea if we still need to train the model or not, based on the accuracy.
Summary
Machine learning applications can help to fix complex problems for the long term such that it can keep learning on future data and keep improving the knowledge, compared to legacy methodologies that help businesses grow faster. There are many libraries and tools available for managing machine learning processes, which takes much of the pain under the boilerplate.
Starting from eCommerce to travel to learning, machine learning development is helping different domains to serve their clients better – without many errors – and empowers them to make scalable smarter platforms available for a huge user base.
Click here for more blogs…
At BoTree Technologies, we build enterprise applications with our 10+ expert ML developers.
We also specialize in RPA, AI, Python, Ruby on Rails, JavaScript and ReactJS.
Consulting is free – let us help you grow!



{kind=link}
{kind=link}
{kind=link}

