Decision Tree Algorithm in Machine Learning
The application of decision tree algorithm is known by all Machine Learning developers. It is a useful supervised Machine Learning algorithm that focuses on probable outcomes and possibilities from decision nodes.
It is the easiest and most popular algorithm for classification. As one of the best Machine Learning algorithms, decision trees can help solve both classification and regression problems.
A decision tree is a flowchart-like tree structure where an internal node represents a feature(or attribute), the branch represents a decision rule, and each leaf node represents the outcome. The topmost decision node in a decision tree is known as the root node.
Decision trees come under the supervised learning algorithms category. As we mentioned, it is primarily used for regression and classification in machine learning models. It provides transparency by offering a single view of all traces and alternatives. Decision tree also assign specific values to problems and decisions, enabling better decision-making.
Read more : Machine Learning: Everything you Need to Know
But do you know how a decision tree works? Most people use it because it’s easy and provides a graphical representation of the problem. In this article, we will look at the decision tree algorithm in detail.
Types of Decision Tree Algorithms
There are two different types of decision tree algorithm for machine learning.
- Classification trees:- In this type of decision tree, there is only one outcome from a set of two. The outcome could be either true for a particular dataset or false. The decision variable is categorical. In this decision tree classifier, categorical classifiers are essential.
- Regression trees:- In this type of decision tree for machine learning algorithms, the outcome is continuous and changes based on the value of variables in the dataset. It is one of the types of decision trees that have continuous target variables. It is also known as a continuous variable decision tree.
The root of the decision tree algorithm is at the top, and it flows upside down. In this Machine Learning algorithm for classification, the branches split downwards and the internal nodes are there to satisfy a particular condition.
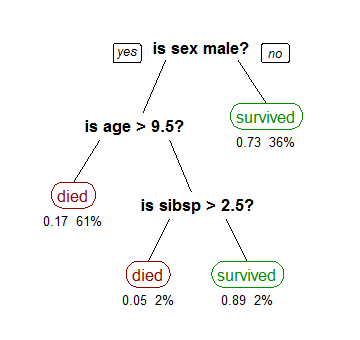
The text in black are the internal nodes, which allows the tree to split into branches based on specific conditions. The end of the branch is the decision or leaf, from which no more branch can pan out. The methodology is also popularized as learning decision tree from data.
Read more: Python AI: Why Python is Better for Machine Learning and AI
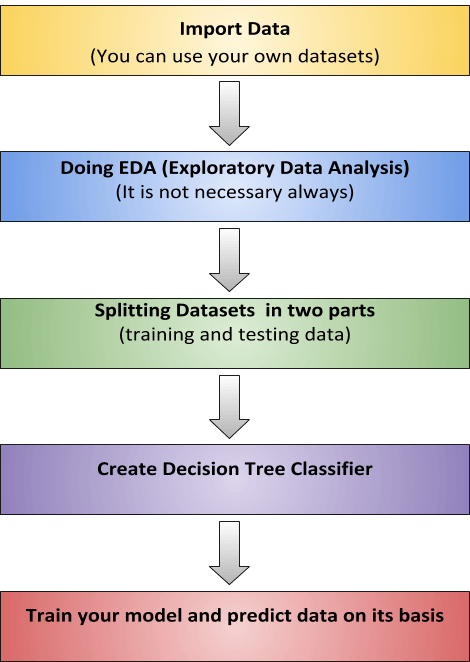
How Does Decision Tree Work ?
Gini Index:
Another decision tree algorithm CART (Classification and Regression Tree) uses the Gini method to create split points.
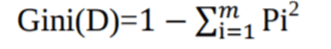
Where pi is the probability that a tuple in D belongs to class Ci.
The Gini Index considers a binary split for each attribute. You can compute a weighted sum of the impurity of each partition.
Entropy:
Entropy is a measure of disorder or uncertainty and the goal of machine learning models and Data Scientists, in general, is to reduce uncertainty.

We simply subtract the entropy of Y given X from the entropy of just Y to calculate the reduction of uncertainty about Y given an additional piece of information X about Y. This is called Information Gain. The greater the reduction in this uncertainty, the more information is gained about Y from X.
Let’s see an example to train model with diabetes data using the above algorithm
Please note that, We are going to use Pandas and Sklearn for training data and using existing dataset of diabetes from Kaggle.
Pros:
- Interpretation and visualization is made easy when Decision trees are used.
- Capturing Nonlinear patterns is easier.
- Normalization of columns is not needed as negligible data preprocessing is required from the user.
- Variable selection can be more efficiently done.
- Feature engineering such as predicting missing values can be done very efficiently using this algorithm.
- There are no assumptions about distribution because decision tree has a non-parametric nature.(Source)
Cons:
- Overfitting noisy data and sensitivity to noisy data is a con.
- Nominal variation in data can result in different decision tree. To reduce this con bagging and boosting algorithms are used.
- Before creating a decision tree it is suggested to balance out the dataset as decision trees are biased to imbalanced dataset.
Conclusion
The above decision tree examples showcase how this algorithm for classification problems is useful for Machine Learning applications. We have covered what is a decision tree, the advantages of decisions trees, and how a decision tree algorithm works.
Decision tree is very easy to understand and communicate. It provides an excellent visual illustration of the data and the dendrogram gives a good look at the relationship between objects.
Consulting is free – let us help you grow!



{kind=link}
{kind=link}
{kind=link}